단편 서열 매핑 통계를 이용한 유전자 변이 시뮬레이터
- 이상민 / 부산대학교 전자전기컴퓨터공학과
- 지도교수 : 이도훈 교수님
요약
키워드 : 시뮬레이터, 차세대시퀀싱, 단편 서열 매핑, 버로우즈-흴러 변환, 합성 서열 생성
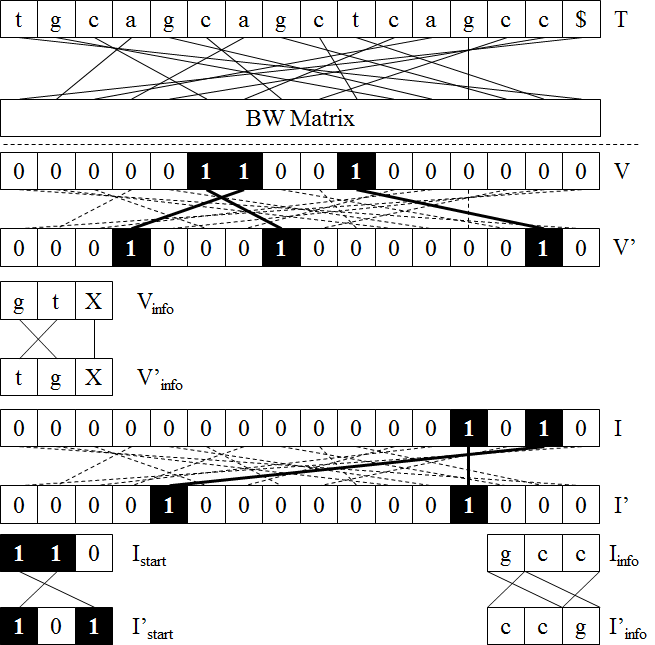
I. 서론
II. 관련 연구
III. 문맥 기반의 오류 정보 색인
IV. 합성 서열 시뮬레이션
V. 실험 및 결과
VI. 결론
I. 서론
차세대 시퀀싱(NGS, Next Generation Sequencing) 기술이 도입된 이후 적은 비용으로 대규모의 서열 데이터와 리드(short-read)를 생산하는 것이 가능해졌다. 생산된 유전체 데이터를 계산적으로 처리하여 다양한 종류의 유전체 기능을 해독하고, 나아가서는 유전자 변이의 형태와 위치에 따른 질병의 유전적 원인을 규명하는 등의 생물정보학적 연구가 활발히 진행되고 있다.
유전체 분석에 사용되는 도구들은 시퀀싱 기계로부터 생산된 대용량의 서열 데이터를 처리하고 이로부터 연구자들이 생물학적 의미를 쉽게 규명할 수 있도록 도와주는 역할을 한다. 유전체 데이터와 관련하여 다양한 분야에서 요구가 발생하고 있는 만큼 현재까지 많은 종류의 유전체 분석 도구가 개발되어 왔다. 유전체 분석 도구의 성능에 대한 상호 객관적인 평가의 중요성이 대두되고 있다. 대용량의 유전체 데이터에 대하여 시간 및 공간적으로 얼마나 효율적이며, 정확하게 필요한 정보를 탐색하는지에 대한 여부는 유전체 데이터 분석 연구의 진척 속도나 품질의 향상에 큰 영향을 미친다. 따라서 대상 영역에서 사용되는 유전체 분석 도구가 효율적인지를 알아내는 것은 중요한 문제 중의 하나이다.
특히 NGS 리드를 이용한 유전체 분석 도구에 대한 상호 비교 평가에 있어서 사용되는 데이터도 매우 중요하다. 우선 평가 표준으로 실제 유전체 데이터를 사용하는 것에는 여러가지 문제점이 있다. 가장 큰 문제점은 실제 시퀀싱 과정으로부터 원래 유전체 서열을 정확히 해독할 수 없다는 점이다. 시퀀싱 기계로부터 얻을 수 있는 정보는 전체 유전체 서열 그 자체가 아니라 짧은 길이의 리드들인데, 때문에 이 리드들이 원래 서열의 어느 부분에 위치하고 있었는지 여부조차 알 수가 없다. 또한 실제 데이터는 비교 실험에 필요한 규모로 임의 생성이 힘들며, 차세대 시퀀싱 기술 이후로 비용이 저렴해졌다고는 하지만 반복적인 대규모 실험에 소요되는 비용은 여전히 부담스러운 것이 사실이다. 또한 인간 유전체의 분석이 필요한 경우에 자료를 제공하는 지원자에 대한 개인정보 보호 문제가 대두될 수 있다.
이 문제를 해결하기 위하여 다양한 유전자 변이 및 단편 서열 생성 시뮬레이터들이 개발되어왔다. 시뮬레이터들은 다양한 매개변수를 통해 서열의 유전자 변이를 모사하고, 이로부터 다시 단편 서열을 생성해내는 기능을 한다. 이를 통해 원하는 형태의 데이터를 필요한 규모만큼 생산하는 것이 가능해졌다. 시뮬레이터의 개발에 있어서 가장 중요한 과제는 가능한 실제 데이터의 특성을 최대한 반영하는 것이다. 그러나 대부분의 시뮬레이터들이 유전자 변이를 시뮬레이션함에 있어서 각 변이에 대한 확률을 입력받아 조절하는 것이 대부분이다.
본 논문에서는 합성 유전체 서열을 생성하는 과정에서 유전자 변이를 서열의 문맥에 기반하여 시뮬레이션하는 기법을 제안한다. 기존의 시뮬레이터들이 단순히 각 뉴클리오타이드마다 독립적인 사건 확률을 부여하였다면, 제안 기법은 각 지점 주변에 어떤 서열 문맥이 존재하는지에 따라 변이 확률을 계산하여 적용할 수 있는 방법을 제시한다. 실제 유전체 단편 서열이 참조 서열 상에 매핑된 결과를 통해 유전자 변이와 시퀀싱 오류에 관한 문맥적 정보를 얻어 이를 색인하고, 새로운 유전체 서열과 단편 서열을 생성하는 과정에서 이를 반영한다.
본 논문의 구성은 다음과 같다. 2장에서는 유전체 서열 시뮬레이터에 관련된 연구와 제안 기법을 설명하기 위해 필요한 배경 지식을 설명한다. 3장에서는 문자열 상에서 발생하는 사건 정보를 색인하여 버로우즈-휠러 변환을 이용하여 문맥에 기반한 확률 계산을 수행하는 방법을 제안하며, 이를 활용하여 4장에서 유전체 변이 정보와 단편 서열의 기계적 오류를 시뮬레이션 하는 방법을 제안한다. 5장에서는 제안 기법을 이용하여 합성 유전체 서열 및 단편 서열을 생성하는 실험을 수행하고 그 결과를 검토하며, 6장에서 결론을 맺는다.